- Spring (IoC): Usaremos la Inversión de Control de éste framework general para configurar por inyección de dependencias las clases a utilizar ganando así flexibidad. También usaremos de él, algunas clases de apoyo útiles para los test de JUnit.
- JPA (Java Persistence Api): Estándar para la persistencia de objetos en Java.
- EclipseLink: Motor ORM que usaremos como proveedor JPA. Gracias a Spring podemos reemplazar EclipseLink por otro ORM como Hibernate o OpenJPA fácilmente.
- JUnit: Framework para crear test unitarios.
- DBUnit: Librería de utilidades para escribir test con Base de Datos.
- HSQL-DB: Motor de Base de Datos en memoria, muy útil para los test.
El código fuente se encuentra en un proyecto de Netbeans pero es muy sencillo copiar todas nuestras clases y agregar todas las librerías dependientes del directorio lib en tu IDE favorito.
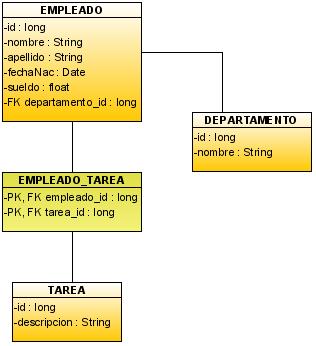
El Domino
Como modelaremos sólo la capa de acceso a datos no es necesario conocer demasiado del negocio, sólo necesitamos saber que clases del domino serán las persistentes como muestra el siguiente diagrama de clases. Un empleado trabaja para un departamento y puede tener asignadas algunas tareas.

De esta forma tendremos un modelo de datos con cuatro tablas. La tabla EMPLEADO, DEPARTAMENTO, TAREA y EMPLEADO_TAREA para la relación muchos a muchos entre Empleado y Tarea.
La clase Departamento:
@Entity
public class Departamento implements Serializable {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nombre;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getNombre() {
return nombre;
}
public void setNombre(String nombre) {
this.nombre = nombre;
}
@Override
public String toString() {
return "Departamento{" + "nombre=" + nombre + '}';
}
}
En éste caso el mapeo del nombre de la clase a la tabla se produce de forma implícita porque tienen el mismo nombre (no es case sensitive). Si la clase se llamaria con un nombre distinto al de la tabla, sería necesario hacer el mapeo del nombre explicito con la anotación @Table(name=”nombreTabla”).
Tambien podemos observar que la anotación @Id seguida de @GeneratedValue, especifica que el campo sera la clave primaria y el valor sera autogenerado por la base de datos con la estrategia IDENTITY.
La clase Tarea:
@Entity
public class Tarea implements Serializable {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String descripcion;
public String getDescripcion() {
return descripcion;
}
public void setDescripcion(String descripcion) {
this.descripcion = descripcion;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
}
La clase Empleado:
@Entity
public class Empleado implements Serializable {
@Id @GeneratedValue(strategy=GenerationType.IDENTITY)
private long id;
private String nombre;
private String apellido;
@Temporal(javax.persistence.TemporalType.DATE)
private Date fechaNac;
private float sueldo;
@ManyToMany
@JoinTable(name="EMPLEADO_TAREA",
joinColumns=@JoinColumn(name="EMPLEADO_ID"),
inverseJoinColumns=@JoinColumn(name="TAREA_ID"))
private Collectiontareas;
@ManyToOne
@JoinColumn(name="DEPARTAMENTO_ID")
private Departamento departamento;
public String getApellido() {
return apellido;
}
public void setApellido(String apellido) {
this.apellido = apellido;
}
public Departamento getDepartamento() {
return departamento;
}
public void setDepartamento(Departamento departamento) {
this.departamento = departamento;
}
public Date getFechaNac() {
return fechaNac;
}
public void setFechaNac(Date fechaNac) {
this.fechaNac = fechaNac;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getNombre() {
return nombre;
}
public void setNombre(String nombre) {
this.nombre = nombre;
}
public float getSueldo() {
return sueldo;
}
public void setSueldo(float sueldo) {
this.sueldo = sueldo;
}
public CollectiongetTareas() {
return tareas;
}
public void setTareas(Collectiontareas) {
this.tareas = tareas;
}
@Override
public String toString() {
return "Empleado{" + "id=" + id + ", nombre=" + nombre + ", apellido="
+ apellido + ", departamento=" + departamento + '}';
}
}
Nótese el mapeo de las colecciones, en especial la colección tareas que representa la relación muchos a muchos con la tabla TAREA mapeada con la tabla intermedia EMPLEADO_TAREA gracias a la anotación @ManyToMany y la anotación @JoinTable
Clases DAO
Este patrón de diseño es usado como Objeto de Acceso a Datos. En nuestro ejemplo definimos su interface para acceder a los datos de la entidad Empleado:
public interface EmpleadoDao {
public Empleado buscarPorId(long id);
public void guardar(Empleado empleado);
public void borrar(Empleado empleado);
public Empleado buscarPorNombre(String nombre);
public CollectionlistarTodos();
public CollectionlistarPorDepartamento(Departamento departamento);
}
Y su implementación para JPA:
@Repository
@Transactional
public class EmpleadoDaoJPA implements EmpleadoDao {
@PersistenceContext
private EntityManager em;
@Override
public Empleado buscarPorId(long id) {
return em.find(Empleado.class, id);
}
@Override
public void guardar(Empleado empleado) {
em.persist(empleado);
em.flush();
}
@Override
public void borrar(Empleado empleado) {
em.remove(empleado);
}
@Override
public Empleado buscarPorNombre(String nombre) {
Query query = em.createQuery(
"SELECT e FROM Empleado e WHERE e.nombre=:nom")
.setParameter("nom", nombre);
return (Empleado) query.getSingleResult();
}
@Override
public CollectionlistarTodos() {
Query query = em.createQuery("SELECT e FROM Empleado e");
return query.getResultList();
}
@Override
public CollectionlistarPorDepartamento(Departamento departamento) {
Query query = em.createQuery(
"SELECT e FROM Empleado e WHERE e.departamento=:dpto")
.setParameter("dpto", departamento);
return query.getResultList();
}
}
La anotación @Repository es una anotación Spring que indica que es una clase que deberá ser instanciada automáticamente como un Singleton.
La anotación @Transactional le indica a Spring que las operaciónes de datos realizadas por JPA en esa clase serán transaccionales.
La anotación @PersistenceContext inyecta un EntityManager a la variable de clase em para poder acceder a las operaciones que nos expone JPA en su api.
Obsérvese además, las querys creadas en el lenguaje de consultas de JPA JPQL que nos permite consultar manteniendo las características de la orientación a objeto, tales como la herencia.
El archivo persistence.xml
org.eclipse.persistence.jpa.PersistenceProvider
alevouilloz.entity.Empleado
alevouilloz.entity.Departamento
alevouilloz.entity.Tarea
Si buscamos dentro del paquete META-INF nos encontraremos con el archivo persistence.xml. Este archivo es la unidad de persistencia que configura JPA. Como podemos apreciar se indica el proveedor de persistencia que se usará, en nuestro caso EclipseLink. Además se enumeran las clases que deben ser mapeadas por el motor ORM. También es posible configurar aquí la fuente de conexión JDBC que se usará, pero en nuestro ejemplo lo haremos en el contexto de aplicación de Spring.
Importante: Al iniciarse la aplicación, la JVM por defecto buscará éste archivo dentro del paquete META-INF.
El archivo applicationContext.xml:
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd">
class="org.springframework.beans.factory.config.PropertiesFactoryBean">
false
En el paquete resource del directorio test, se encuentra el archivo applicationContext.xml. Este archivo es el contexto de aplicación del framework Spring. En él indicaremos entre otras cosas, la fuente de conexión JDBC con la base de datos y las clases DAO que usaremos.
En nuestro ejemplo, el bean definido con id empleadoDao no es necesario, ya que como vimos anteriormente, nuestra implementación EmpleadoDaoJPA está anotada como @Repository y gracias al component-scan de Spring, ésta es cargada automáticamente y luego es inyectada cuando una clase necesita una instancia de su interface usando la anotación @Autowired. En el caso que la Interface EmpleadoDao tenga varias implementaciones, es útil definir el bean con un id en el contexto para que luego pueda indicarse que implementación DAO será la inyectada.
Preparando la Base de Datos para el Test
Por medio del script ddl.sql del paquete resource que ejecutamos, definimos la creacion de las tablas necesarias.
DROP TABLE EMPLEADO if exists;
DROP TABLE DEPARTAMENTO if exists;
DROP TABLE TAREA if exists;
DROP TABLE EMPLEADO_TAREA if exists;
CREATE TABLE EMPLEADO (
id integer NOT NULL IDENTITY,
nombre varchar(255) NOT NULL,
apellido varchar(255),
sueldo float,
fechaNac Date,
departamento_id integer
);
CREATE TABLE DEPARTAMENTO (
id integer NOT NULL IDENTITY,
nombre varchar(255) NOT NULL
);
CREATE TABLE TAREA (
id integer NOT NULL IDENTITY,
descripcion varchar(255) NOT NULL
);
CREATE TABLE EMPLEADO_TAREA (
id_empleado integer NOT NULL,
id_tarea integer NOT NULL,
);
En el archivo initDataSet.xml definimos el DataSet para que el framework DBUnit cargue algunos datos de prueba en las tablas de la base de datos.
Escribiendo el Test para el DAO: EmpleadoDaoJPA
@ContextConfiguration(locations = {"classpath:resources/applicationContext.xml"})
@RunWith(SpringJUnit4ClassRunner.class)
@TransactionConfiguration(transactionManager = "transactionManager")
@Transactional
public class EmpleadoDaoJPATest {
@Autowired
private EmpleadoDao empleadoDao;
@Autowired
@Qualifier(value = "HSQLDataSource")
private DataSource datasource;
@Before
public void setUp() throws Exception {
//Creamos las tablas necesarias para el test antes de cargar los datos
SimpleJdbcTemplate temp = new SimpleJdbcTemplate(datasource);
SimpleJdbcTestUtils.executeSqlScript(
temp, new ClassPathResource("resources/ddl.sql"), false);
//Cargamos la BD con los datos iniciales
Connection conn = datasource.getConnection();
IDatabaseConnection dbUnitCon = new DatabaseConnection(conn);
FlatXmlDataSetBuilder dsBuilder = new FlatXmlDataSetBuilder();
IDataSet dataSet = dsBuilder.build(new File("./test/resources/initDataSet.xml"));
try {
DatabaseOperation.CLEAN_INSERT.execute(dbUnitCon, dataSet);
} finally {
DataSourceUtils.releaseConnection(conn, datasource);
}
}
@Test
public void testBuscarPorId() {
Empleado result = empleadoDao.buscarPorId(1L);
assertNotNull(result);
System.out.println("Empleado encontrado: " + result);
}
...
Es posible cargar el archivo de contexto de Spring por medio de la API, pero en el ejemplo lo hacemos por medio de la anotación @ContextConfiguration donde le indicamos además su ubicación. Si no se indica la ubicación Spring asume que el archivo contexto de aplicación se encuentra en el mismo paquete de la clase de inicio y su nombre es el de la clase concatenando “-config.xml”.
La anotación @RunWith(SpringJUnit4ClassRunner.class) nos da soporte de Spring para JUnit 4.
Podemos ver que la variable de clase empleadoDao al estar anotada como @Autowired será inyectada con la implementación de EmpleadoDao que sea encontrada en el contexto.
De forma similar también será inyectado el DataSource declarado en la variable datasource, pero esta vez indicamos explícitamente con la anotación @Qualifier que sea con el bean llamado “HSQLDataSource”. En el caso de que existan varios beans del mismo tipo y si no usamos @Qualifier, Spring no sabrá que implementación inyectar y nos arrojará una excepción informando éste inconveniente. En nuestro ejemplo no es necesario especificar el DataSource a inyectar ya que en el contexto existe un solo bean declarado, pero queda a modo ilustrativo.
El método setUp() anotado con @Before de JUnit4 se ejecuta al comienzo de cada test y prepara la Base de Datos con la ayuda de algunas clases de utilidades de DBUnit, cargando el dataset con los datos iniciales para las pruebas.
Esto es todo. Espero que les haya sido útil, y ya saben: cualquier duda, comenten.
No hay comentarios:
Publicar un comentario